4.8 (21,636) reviews
4.8 (21,636) reviews





 Git
Git
 Bitbucket
Bitbucket
 Docker
Docker
 AWS
AWS
 NLKT
NLKT
 MySql
MySql
 Tableau
Tableau
 Plotly
Plotly
 GitHub Copilot
GitHub Copilot
 Computer Vision
Computer Vision
 BARD
BARD
 Open AI
Open AI
 Synthesia
Synthesia
 Generative AI
Generative AI
 Power BI
Power BI
 MS Azure
MS Azure
 NLP
NLP
 Yellowbrick
Yellowbrick









































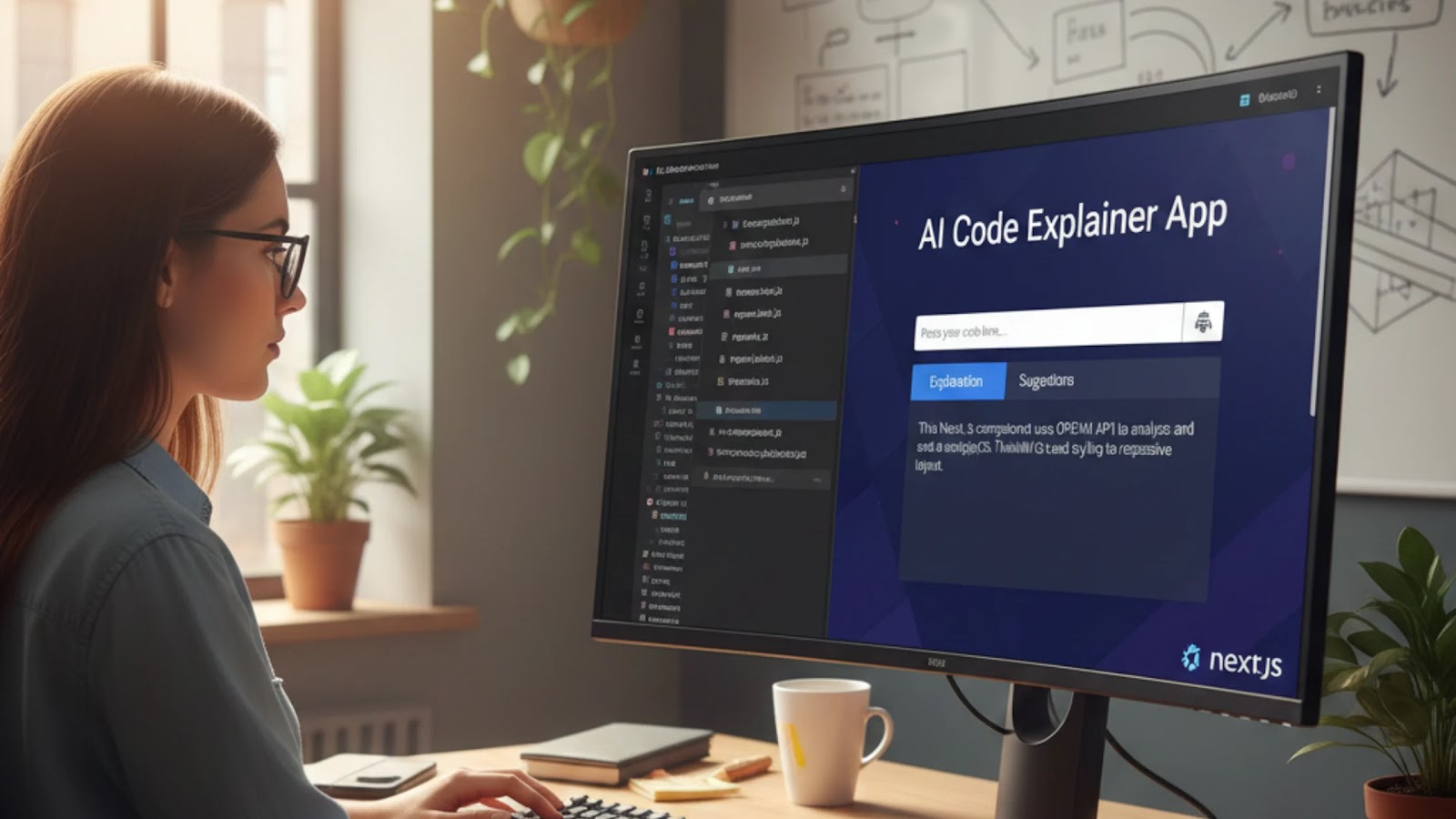
A full stack data science course
equips individuals with comprehensive skills across the entire data science
lifecycle, from data collection and cleaning to model deployment and
monitoring. This training prepares individuals for various career options and
job opportunities in India, which is experiencing a burgeoning demand for data
science professionals across multiple industries. Here's an overview of the
career paths and opportunities available:
- Data Scientist: Analyze complex
data sets to provide insights, build predictive models, and solve business
problems.
- Skills Needed: Statistics, machine learning, data visualization, programming (Python/R), data wrangling.
- Data Analyst: Interpret data,
analyze results using statistical techniques, and provide ongoing reports.
- Skills Needed: Excel, SQL, data visualization tools (Tableau, Power BI), basic statistical knowledge.
- Machine Learning Engineer: Design,
implement, and maintain machine learning models and systems.
- Skills Needed: Advanced programming (Python, Java, C++), machine learning frameworks (TensorFlow, PyTorch), software engineering.
- Data Engineer: Develop, construct,
test, and maintain architectures such as databases and large-scale processing
systems.
- Skills Needed: SQL, NoSQL, Hadoop, Spark, data pipeline tools, ETL (Extract, Transform, Load).
- Business Intelligence (BI)
Developer: Develop and manage BI solutions, create reports and dashboards to
support business decision-making.
- Skills Needed: BI tools (Tableau, Power BI), SQL, understanding of business processes.
- AI Research Scientist: Conduct
research in artificial intelligence and machine learning, develop new
algorithms and models.
- Skills Needed: Deep learning, advanced mathematics, programming, research methodologies.
- Big Data Specialist: Handle large
datasets, perform data mining, and develop scalable data processing systems.
- Skills Needed: Hadoop, Spark, NoSQL databases, programming (Python, Scala, Java).
A full stack data science course
offers a robust foundation for various career paths in India’s thriving data
science landscape. With the right skills and qualifications, professionals can
explore numerous opportunities across diverse industries, contributing to
significant business and technological advancements.












 Read more
Read more